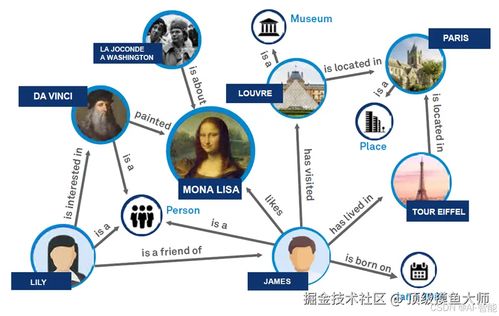
在当今人工智能蓬勃发展的时代,大模型与知识图谱的结合正成为推动认知智能纵深发展的关键技术路径。知识图谱以其强大的结构化知识表示与推理能力,为大模型提供了坚实的知识底座,而大模型则以其卓越的自然语言理解与生成能力,极大地赋能了知识图谱的构建与应用。本文将深入探讨如何在大模型的驱动下,高效构建知识图谱,涵盖从核心理论、技术选型到工程落地的完整实践指南。
一、 核心理念:大模型与知识图谱的协同增效
大模型(如GPT、文心一言、通义千问等)与知识图谱并非替代关系,而是互补与协同的“双引擎”。
- 大模型赋能知识图谱构建:传统知识图谱构建严重依赖人工规则与标注,成本高昂且扩展性差。大模型凭借其深厚的语言知识,可以自动化或半自动化地完成实体识别、关系抽取、属性填充、知识融合等核心任务,显著提升构建效率与规模。
- 知识图谱增强大模型能力:大模型虽知识广博,但存在“幻觉”、事实性错误和可解释性差等问题。知识图谱作为结构化的“事实记忆库”,可以为大模型提供精确、可靠、可追溯的知识来源,用于事实核查、增强推理、提升回答的准确性与可信度。
二、 技术架构与核心模块
一个典型的大模型驱动型知识图谱构建与应用系统,通常包含以下核心模块:
- 数据获取与预处理模块:
- 数据源:包括非结构化文本(新闻、报告、论文)、半结构化数据(网页表格、JSON)和结构化数据(数据库)。大模型尤其擅长处理非结构化文本。
- 预处理:文本清洗、分句、分词等,为后续信息抽取做好准备。
- 大模型驱动的信息抽取模块(核心):
- 实体识别与链接:利用大模型的Few-shot/Zero-shot能力,或通过微调(Fine-tuning)特定领域模型,识别文本中的实体(如人物、机构、概念),并将其链接到知识图谱中的已有节点。
- 关系与属性抽取:通过精心设计的提示词工程(Prompt Engineering),引导大模型从句子或段落中抽取出实体间的语义关系(如“创始人”、“位于”)及实体的属性(如“成立日期”、“注册资本”)。
- 事件抽取:对于更复杂的动态知识,可抽取事件(如“公司上市”、“产品发布”)及其相关要素(时间、地点、参与者)。
- 知识融合与存储模块:
- 知识融合:对不同来源抽取的、可能存在冲突或冗余的知识进行对齐、消歧与合并。大模型可以辅助进行实体消歧和冲突消解。
- 知识存储:将结构化后的知识存入图数据库(如Neo4j, Nebula Graph, JanusGraph)或RDF三元组库,形成可查询、可推理的知识图谱。
- 知识推理与应用模块:
- 推理与补全:基于图谱的拓扑结构,利用规则或嵌入表示进行隐含关系推理,补全缺失知识。
- 智能应用:
- 增强检索(RAG):将知识图谱作为外部知识源,与大模型结合,实现精准、可溯源的问答系统。
- 决策支持:在金融、医疗、政务等领域,提供基于深度关系的分析与洞察。
- 语义搜索:超越关键词匹配,实现基于实体和关系的精准语义搜索。
三、 实战流程与开发要点
第一步:定义领域与模式
明确知识图谱的应用场景(如企业风控、医疗诊断、智能客服),设计本体(Ontology),即定义实体类型、关系类型和属性体系。这是图谱的“骨架”。
第二步:技术选型与数据准备
- 大模型选择:根据领域专业性、成本、性能需求,选择通用大模型API(如OpenAI GPT-4, 国内主流平台API)或开源可微调模型(如LLaMA系列、ChatGLM、Qwen)。领域性强的任务建议进行有监督微调。
- 图数据库选择:根据数据规模、查询复杂度、并发需求选择。Neo4j适合快速原型和丰富的关系查询;Nebula Graph适合超大规模分布式场景。
第三步:实现信息抽取流水线
- Prompt设计:这是与大模型交互的核心。设计清晰、具体、包含示例(Few-shot)的提示词,明确指令、输入格式和输出格式(如要求输出标准JSON)。例如:“请从以下句子中抽取出所有公司实体和它们之间的关系。关系类型限定为:投资、竞争、合作。以JSON格式输出:{"entities": [...], "relations": [...]}”。
- 任务分解:复杂任务可拆分为“实体识别→关系分类”等多个子步骤链式调用,以提高准确性。
- 后处理与校验:设计规则或利用小规模标注数据对模型输出进行清洗、格式化与质量校验。
第四步:构建、存储与维护图谱
- 将抽取的(实体,关系,实体)三元组和实体属性批量导入图数据库。
- 建立定期的知识更新与迭代机制,实现图谱的动态演化。
第五步:开发上层应用
- 利用图查询语言(如Cypher, nGQL)从图谱中检索信息。
- 构建应用接口,将图谱检索结果与大模型的生成能力结合,打造最终应用。
四、 挑战与未来展望
- 挑战:大模型生成的不稳定性与成本控制;复杂、隐含关系的抽取精度;海量知识下的高效存储与检索;领域知识的持续注入与更新。
- 展望:大模型与知识图谱的融合将更加紧密。向量数据库将与图数据库结合,形成“向量-图”混合存储,同时支持语义相似性搜索与复杂关系推理。自监督学习、强化学习将进一步优化知识抽取与推理过程,推动面向复杂场景的“认知智能系统”走向成熟。
构建大模型驱动的知识图谱,是一场将非结构化信息转化为可计算、可推理的结构化知识的系统工程。它不仅是技术的融合,更是对业务深刻理解的体现。从明确场景出发,以小步快跑的方式迭代验证,方能真正释放“大模型+知识图谱”的联合价值,赋能千行百业的智能化转型。